最近过年放假,加上突如其来的在家办公,时间显得有点充裕,突然就想写写什么东西,决定来聊一聊接口的设计。
接口规范这个东西,网上看到的,大部分都是服务端同学之间针对开发层面的交流,当然也看到有一些前端同学在吐槽接口不好用。
作为一个接口使用者,在日常业务中,的确遇到过很多结构设计随意、字段命名随意的接口(大部分是为了活动而临时设计),而通常这种接口也缺少对应的文档(因为赶工期),所以理解起来比较费时间,遇到架构设计不合理的情况时,也容易导致在业务的实现过程中,需要写很多冗余的代码来输出最终的数据。
所以想从前端的角度,以一个接口消费者的身份来谈一谈如何设计一套比较合理的接口,本文主要分为两部分:“接口的基本数据格式”和“接口的业务数据格式”。
本文的目的是想减少前后端对接过程中产生的沟通问题,还有优化一些可以避免的错误,甚至于你可以不提供接口文档,前端也能快速上手你的接口。
接口的基本数据格式
目前主流的数据返回格式都是以 JSON 的形式,JSON 的字段是以 { key: value } 的形式成对出现的。
其中 key 是用来读取指定数据的标识,并且在同一个层级的数据里,是唯一的存在,而 value 就是这个 key 所对应的数据信息。
例如:在一个公司里,你的工号就是你的 key ,并且这个工号是唯一的,只属于你,可以通过这个工号来找到你的信息,而 value 此时就对应了你的姓名、入职时间等员工信息。
基本数据格式,是围绕 JSON 格式规范层面上来讲的。
关于 key 的规范要求
key 是用来读取指定数据的标识,在 JSON 的格式规范中,统一用 双引号 套起来,前端读取的时候,会通过 data['key'] 或者 data.key 的格式获取对应字段的数据。
在实际的项目接入中,遇到的 key 在命名上问题不少,有的是缩写随意,有的是语义不明,有的是上下级重复命名,更有的是用拼音甚至是拼音缩写。
我知道在赶工期的时候,服务端同学并不是那么乐意把时间投入到写文档上面,希望前端能够一看就知道接口怎么用,那么写好规范化的 key,就能够减少很多理解上的偏差,而这只需要花费一丢丢时间,所谓磨刀不误砍柴工,性价比是非常高的!
所以建议在定 key 的时候,遵循一些必要的规范:
- 语义化来命名 key,并且遵循下划线命名法或者驼峰命名法
比如:定义一个用户信息字段,推荐使用 userInfo 或者 user_info 作为 key ,而 userinfo 则不建议使用,更不允许使用 data1 、 data2 这样毫无意义的命名方式。
确定好一套命名法之后,这一套接口就需要遵循同一种书写风格,不要混搭使用。
- 包含“多个结果”的字段,注意名词的复数形式的使用
比如:多个标签使用 tags 而不是 tag ,多个图片使用 pictures 而不是 picture
这里有一个默认的使用窍门:
1、当 value 为普通数组时,使用 “名词复数” 的形式命名 key
2、当 value 为嵌套了 JSON 对象的数组时,使用 名词 + list结尾 的形式来命名 key
比如:
{
"tags": ["食物", "粤菜", "卤水"],
"memberList": [
{
"uid": 111,
"name": "张三",
"age": 22
},
{
"uid": 222,
"name": "李四",
"age": 27
}
]
}- 判断查询类的字段,注意动词的配合
通常这种情况代表会返回一个布尔值(true / false),常用的有以下几种:
| 动词 | 含义 | 例子 |
|---|---|---|
| is | 是否符合某个条件 | { "isLogined": true, "isVip": true } |
| has | 是否包含某类数据 | { "hasCoupon": true, "hasAvatar": false } |
| can | 是否能够进行某个操作 | { "canPublish": false } |
- 使用合理的缩写
缩写是为了提高开发时的书写效率,但是也要遵循缩写规范,或者仅使用普遍认知的缩写方式,不要自己创造一些只有自己看得懂的缩写方式。
比如:等级 level 使用缩写 lv ,message 使用缩写 msg ,error 使用缩写 err,user id 使用缩写 uid,都是允许的,但是 user name 缩写成 un 就会一脸懵逼!!!
- 避免使用重复的 key
在同一级的关系里,key 是唯一,如果有重复,后添加的会覆盖之前添加的。
比如:已经有了一个{ "name": "张三" }的情况下,你继续添加一个{ "name": "李四" },那最终读取 name 字段的时候,获取到的只有“李四”。
不同层级允许使用相同的 key 命名,但是,容易造成 bug ……(我是真的遇到过这样的接口!)
我举一个很恶心的例子(请不要这样写),比如不同层级都使用了 “data” 作为 key :
{
"code": 200,
"data": {
"category": "news",
"data": [
{
"subject": "This is a subject.",
"content": "This is a content."
},
{
"subject": "This is another subject.",
"content": "This is another content."
}
]
}
}假设前端采用 axios 发起的 ajax 请求,那么返回数据的时候,本身获取 JSON 需要用到 response.data 就包含了一个 data ,如果要获取第一个 subject ,则需要使用 response.data.data.data[0].subject 连续的写上 3 个 data ,非常容易出错!!!
以上部分就是对 key 的规范约束,如果能注意这些问题的话,我相信就算你来不及写接口文档,前端同学一看数据格式也能马上明白你的接口各个字段的含义和用法。
关于 value 的规范要求
在 JSON 规范中,value 对应六种不同的数据类型,不同类型的表达形式也有所区分,具体如下:
| 类型 | 特征 | 例子 |
|---|---|---|
| String 字符串 | value 套在双引号中 | { "name": "张三" } |
| Number 数字 | value 为整数或者是浮点数 | { "age": 18, "weight": 84.83 } |
| Boolean 布尔值 | value 为 true 或者是 false | { "isLogined": true, "isVip": false } |
| Array 数组 | value 套在方括号中 | { "tags": ["中餐", "粤菜", "卤水", "荤菜"] } |
| Object 对象 | value 套在花括号中 | { "userInfo": { "name": "张三", "age": 18 } } |
| Null 空类型 | value 为 null | { "girlFriend": null } |
那么什么情况应该用什么类型的数据呢?我们一个一个类型来解析一下:
- String 字符串
最常见的数据格式,理论上所有类型都可以用 string 的形式返回,然后再转换解决(虽然可以,但是没必要……)
一般用于文本展示,URL 链接、图像地址、或者一些要渲染成 HTML 代码的源码部分,我们可以选择字符串传输。
另外对于以下其他类型都不适合的场景,也都可以选择字符串来传输,不过如果能用对应类型的数据,最好还是用他们应该用的类型。
- Number 数字
当你需要返回的值,只用一个数值即可表达的时候,就选择用 Number 类型。
常用的有 “时间戳、用户 uid 、年龄、价格、页码、物品数量” 等场景。
- Boolean 布尔值
当你需要对一个判断条件返回结果的时候,就选择用 Boolean 类型。
常用的场景有“判断用户是否已登录、判断用户是否 vip 会员、判断用户是否有优惠资格等等”。
误区:之前遇到有的服务端不知道是什么原因,在应该返回 false 的时候,返回的是 'false' ,瞬间从 Boolean 变成了 String …… 从假变成了真!!! 这是两个完全不一样的数据!
- Array 数组
当你需要返回“种类一样”的“多个结果”的时候,由于 key 的唯一性限制,这个时候就可以选择用 Array 类型。
比如:返回一个相册图集的图片信息,只需要单纯返回一堆 url ,那么用数组可是非常的方便。
{
"pictures": [
"https://example.com/111.jpg?x-oss-process=image/interlace,1",
"https://example.com/222.jpg?x-oss-process=image/interlace,1",
"https://example.com/333.jpg?x-oss-process=image/interlace,1"
]
}比如:返回一个文章列表,所有的文章结构其实是一样的,那么就可以用包含了对象的数组来输出你的 value 。
{
"articleList": [
{
"id": 111,
"subject": "This is a subject.",
"author": "Petter",
"date": "2020-01-01 11:11",
"content": "This is a content."
},
{
"id": 222,
"subject": "This is another subject.",
"author": "Mary",
"date": "2020-01-02 12:12",
"content": "This is another content."
}
]
}- Object 对象
JSON 本身是一个 Object ,但是支持嵌套 Object ,当你需要对一个字段返回多个相关信息的时候,不应该零散的一个一个单独返回,而是应该集合到一个 Object 里一起返回。
比如:从接口把 “张三” 的注册资料传下来,他的 uid 、昵称、头像等等,都属于相关信息,所以可以按下面这样,返回一个 Object 嵌套到 JSON 里。
{
"userInfo": {
"uid": 111,
"name": "张三",
"age": 24,
"isVip": true
}
}- Null 空类型
空类型一般不会单独作为一个字段的值出现在接口中,更多时候是用来代替某个字段原本应该出现但缺失了的值(也就是这个字段有可能有,有可能没有,出现没有就是 null)。
当数据为空的时候,按照目前约定俗成的做法,基本上有以下三种处理方案(需要前后端同学提前约定选择):
处理方案一:接口返回 null
当一条记录不存在的时候,接口可以返回一个 null 值给前端,前端判断为 null 的时候,就知道这条数据是没有的。
处理方案二:接口不返回该字段
目前运用比较广泛的处理方案就是直接不返回该字段,前端读取到这个字段的时候会返回 undefined ,前端同学在需要用到这个字段的时候,可以灵活处理数据:
直接使用该字段的时候,如果字段不存在,可以预设一个默认值。
const KEY = data.key || 'key'涉及需要二次处理该字段数据的时候,则加上一个判断
if ('key' in data) {
console.log(data.key)
}处理方案三:接口返回该字段类型的默认“空值”
这也是一个运用的比较广泛的方法,这里的 “空值” 是指,根据原来设定的数据类型,返回一个初始默认值,比如:
如果原来是个字符串,那么“空值”就应该是 ''
如果原来是个数组,那么“空值”就应该是 []
如果原来是个对象,那么“空值”就应该是 {}
如果原来是个数字,“空值”则需要根据业务场景来处理,比如“好友数”的默认值可以是 0 ,但是页码的默认值则需要为 1
布尔值也是需要根据业务场景设定默认值,绝大部分场景都需要默认为 false ,比如 “是否 vip”,对于大部分用户来说,初始默认值肯定是设置为 false 为佳。
接口的业务数据格式
讲完基础格式,想聊一聊业务方面的数据格式,顾名思义,是指在业务层面上,虽然符合基本规范,但是在使用上可能会存在的一些人为导致的不合理的地方,从而影响到代码的可复用性、灵活程度等等。
不同接口的“相同数据”
对于一个网站或者 APP ,通常每个不同类型的页面,都会对应不同的接口用以支持需要的数据渲染,但在落实业务的时候,往往会发现,常常出现 “不同的页面” 里包含着 “相同结构的数据” 的情况。
以腾讯新闻为例,它包含了“首页推荐”、“搜索结果页”、“专题聚合页”、“热点聚合页”等不同页面,但这些页面都包含了相同的模块 —— “新闻列表”。
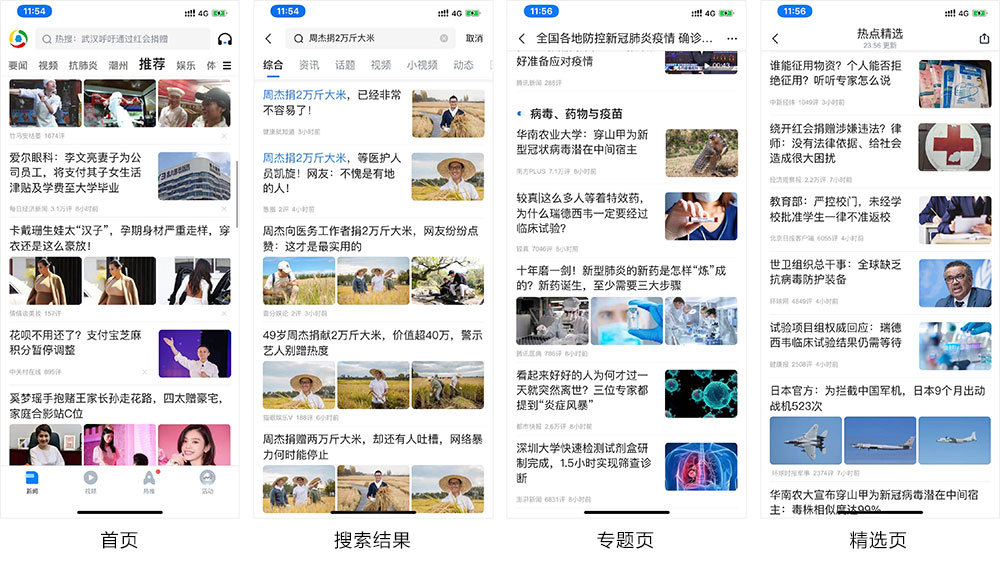
可以看出,“新闻列表”这个模块,每个新闻基本上都是包含了“新闻标题”、“新闻来源”、“评论数”、“发布时间”以及“缩略图(1 - 3 张)”这几个数据信息,那么在指定接口格式的时候,这一部分最好就要统一起来:
{
"newsList": [
{
"newsId": 111,
"subject": "这是一个新闻标题",
"source": "央视新闻",
"commentCount": 1234,
"createTime": 1581850220403,
"thumbs": [
"https://example.com/111.jpg?x-oss-process=image/interlace,1",
"https://example.com/222.jpg?x-oss-process=image/interlace,1",
"https://example.com/333.jpg?x-oss-process=image/interlace,1"
]
},
{
"newsId": 222,
"subject": "这也是一个新闻标题",
"source": "人民日报",
"commentCount": 2333,
"createTime": 1581850528657,
"thumbs": ["https://example.com/444.jpg?x-oss-process=image/interlace,1"]
}
]
}然后再根据每个接口的需要,添加自己本身的特色数据。
这样做的好处是,不管是搜索页的“搜索结果”、推荐页的“猜你喜欢”、专题页的“热点聚合”或者其他哪个页面的数据,对于前端同学来说,它本质都只是一个结构相同的新闻列表,统一字段名和数据结构,能有效降低维护过程中的认知成本、对接成本,并且可以封装成公共方法来处理数据调用,减少差错发生。
业务状态码与反馈信息
在 http 状态码的基础上,接口也都会有自己的一套业务状态码规则,用于反馈接口交互过程中的合法性。
那什么情况下才需要使用状态码?是不是能考虑到的错误都需要提供错误码给前端判断呢?
答案是否定的,状态码过多容易造成维护成本的增加,建议只在一些前端完全无法识别的错误场景才提供错误码。
- 不需要接口反馈状态码的情况
前端可以识别的错误场景可以由前端判断解决,无需接口来处理反馈,简单来说,基于常识性的错误,应该都属于前端可掌握的判断范围。
拿文章列表来举例,文章列表的 url 通常包含着页码信息,用户可以自定义修改页码访问不同的分页数据,有时候因为页码错误的原因,导致文章列表为空,这种情况,按我们上面讲过的方法,此时数据应该是
{
"page": 10,
"articleList": []
}这种情况,实际上前端只需要判断一下数组的长度是否为 0,以及页码大小,即可立即知道列表是否为空,以及为什么会列表为空:
页码小于 1 表示页码错误
页码等于 1 表示当前真的还没有数据(一般出现在新创建的分类列表)
页码大于 1 表示超过最大页数
直接由前端判断后告知用户页码错误情况即可,无需服务端再处理一套页码错误反馈逻辑。
- 需要接口反馈状态码的情况
通俗点来说就是,前端同学:“我怎么知道这东西是真是假”,必须通过服务端确认后才可以得出结论的场景。
还是拿文章列表来举例,比如网站有很多文章分类目录,每个分类对应一个列表,前端在提交请求的时候,是无法知道当前的分类 id 是否存在,这种情况下,就需要由服务端来反馈错误信息:
{
"code": 404,
"message": "文章分类不存在"
}- 反馈信息尽量由接口返回
虽然在遇到错误场景的时候,接口可以只返回 status code ,前端根据接口文档的 code 说明,把提示语写死在页面上,但整个工程的灵活程度就大大降低,每次有所调整,前后端都需要进行修改。
建议接口在返回 code 的时候同时返回 message,前端在弹出 Toast 的时候,文案直接使用服务端返回的 message 来灵活反馈给用户。
这样不管是修改提示文案,还是新增了新的 code ,都无需重新修改页面,容错率高。
- 状态码不一定是数字
目前来说,绝大部分接口在定义 status code 的时候,都是使用数字来作为状态码。
之前在参与开发公司的 Discuz 业务时,发现 DZ 的 mobile API 状态码就很有趣,用的是英文 keyword 来表达:
{
"Message": {
"messageval": "word_banned",
"messagestr": "抱歉,您填写的内容包含敏感信息而无法提交"
}
}{
"Message": {
"messageval": "thread_nonexistence",
"messagestr": "抱歉,指定的主题不存在或已被删除或正在被审核"
}
}因为 Discuz 的系统非常庞大,状态码肯定非常多,如果用数字,不仅容易重复,而且拿到一个数字还不一定能马上知道是什么意思,得去查文档。
而通过这种 keyword 的方式来表达状态码,看到文案就能知道出了什么情况了,非常巧妙!
分割线来个结束语:
以上呢,就是这个假期里,目前对接口业务的一些思考和小结,欢迎点评和讨论!