以往的网站迁移服务器,数据方面的东西都是由服务端直接处理,不过这一次的需求比较特殊,先来看一下需求的几个特征点:
1、改版后的数据源都是来自另外一个平台,新服务器通过接口实现前后端分离,新的数据都来自某款 app,后台也是使用该 app 对应的后台
2、由于第一点,所以旧的 CMS 后台将被下线停用
3、这是一个 10 几年的老网站,数据量庞大,但是大部分旧数据要做舍弃处理(因为大部分内容是资讯,已经过了阅读时效性)
4、有一部分有价值的旧数据需要单独保存,但由于是基于 CMS 更新发布,从服务端导出的都是模板类的代码,无法直接使用
其实简单理解,就比如门户首页本来抓的是门户的资讯,但改版后是抓微博的动态,原来的资讯基本舍弃,只保留一部分专题和文章页,类似酱紫的一个改版迁移 emmm,所以经过商讨,需要由前端来将需要保存的旧页面从客户端保存,再发布上传到新服务器上。
注意事项
这次的需求并不是简单的爬取就完事,拿了需求需要先进行一波分析,拆分了两类注意事项如下:
缺点分析
1、旧页面的编码需要调整(由“gb2312”调整为“utf-8”),否则在新服务器会乱码。
2、旧页面的部分公共模块需要移除(页头通栏、页脚、评论模块、登陆模块等),保留的旧页面将变成纯静态页面。
3、旧页面的统计代码需要更换。
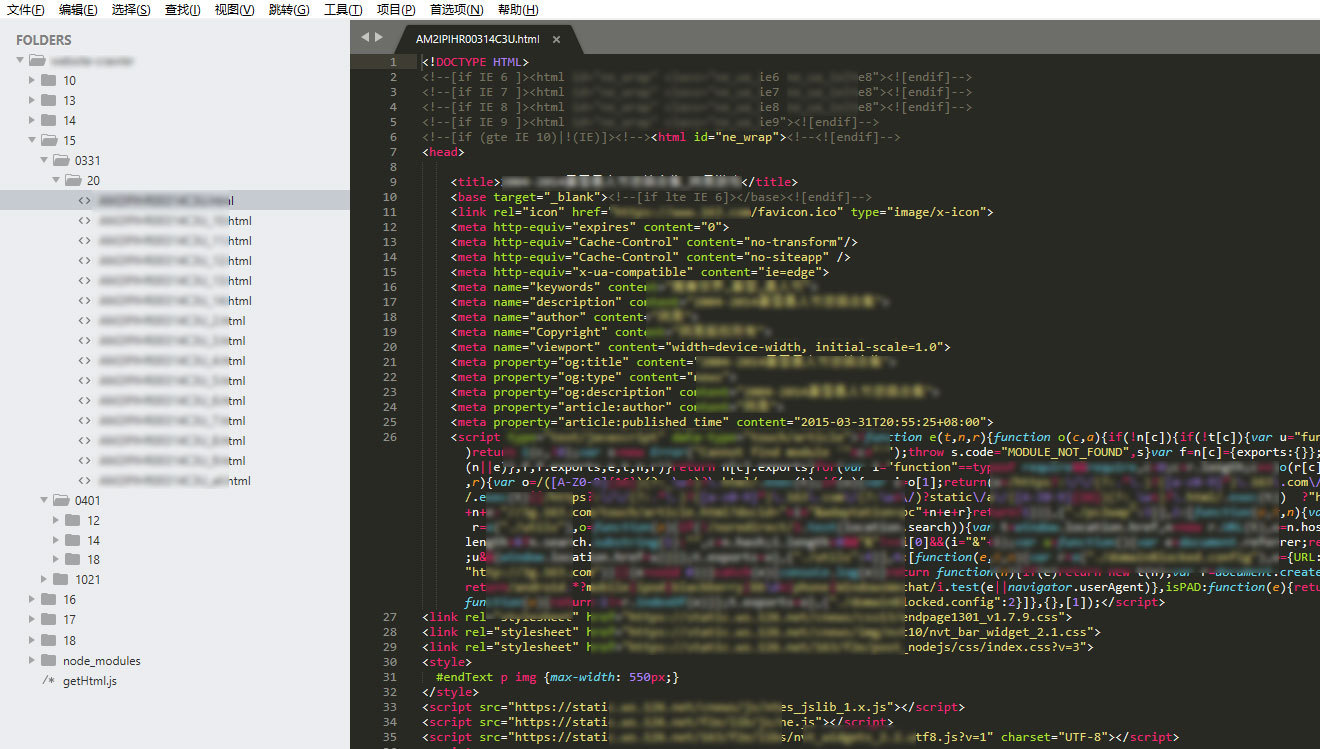
4、旧页面的保存路径必须和原来一模一样(比如文章页一定要遵循原来的 “根目录/年/月/日/hash 文件名.html” 的格式保存),这样才不会造成死链接。
5、需要保存的资源散落在各个专题的引用链接里,需要自己从专题里提取。
优点分析
1、由于是 CMS 输出的文章和专题,所以所有的同类型页面,结构、布局、资源引入完全一致,只需要写一套爬虫代码即可适配抓取(虽然有 3 套文章模板,但结构其实是一样的)。
2、几乎所有的 js 和 css 都是 CDN 资源,也就是无需单独保存这些资源,同步好 html 代码就完事,个别被定制了样式的专题再单独处理一下即可。
3、虽然文章要自己提取链接,但是专题的链接由运营整理提供,可以节省一部分工作量
最后自己这边定下来的方案是用 node 来做爬虫服务器,实现自动化抓取和保存,以下是本次涉及到的工具和模块。
| 工具/模块 | 用途 | api 文档/github |
|---|---|---|
| node.js | 爬虫服务器 | http://nodejs.cn/api/ |
| http 模块 | node 内置的模块,用于获取页面信息,也可以用封装好的 express 框架代替 | http://nodejs.cn/api/http.html |
| fs 模块 | node 内置的模块,用于文件的创建和保存 | http://nodejs.cn/api/http.html |
| mkdirp | node 内置的模块,用于创建多级文件夹(因为 fs 模块的 mkdir 只能一级一级创建,很繁琐) | https://github.com/substack/node-mkdirp |
| iconv | node 本身只支持 utf-8,对于非 utf-8 的网站,要用这个模块进行转码,才不会乱码 | https://github.com/ashtuchkin/iconv-lite/ |
| cheerio | 可选,运行在 node 端的 dom 选择器,api 语法和 jQuery 一样,必要时可用来提取需要的东西 | https://github.com/cheeriojs/cheerio/ |
编写爬虫
这里分两步走:
先提取需要爬取的链接
这一步是汇总成一个数组,这一步就略过了,提取 a 标签的 href,对大家应该都没什么难度。
开始爬取页面
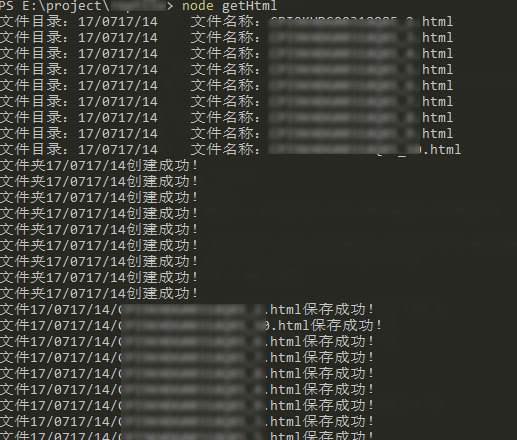
流程:创建项目文件夹,创建一个 getHtml.js 作为主程序文件,打开 node,cd 到这个目录,运行 node getHtml 即可开始爬取。
主程序 getHtml.js 的核心代码如下(模糊掉业务相关信息,仅供参考):
// 引入需要的模块
const http = require('http')
const fs = require('fs')
const iconv = require('iconv-lite')
const mkdirp = require('mkdirp')
// 设置要抓取的网页地址,这里是举例
const urlList = [
'http://chengpeiquan.com/14/0120/10/9KASP7MUSK324C3U.html',
'http://chengpeiquan.com/15/0214/12/3NPRSLDUQWMZ14C3U.html',
'http://chengpeiquan.com/16/0323/11/3S64W57MU00314C3U.html',
]
// 执行抓取
urlList.forEach(function (url) {
// 获取文章的目录结构,提取文件夹层级与文件名
const folder = url.replace(/http:\/\/chengpeiquan\.com\//, '').split('/')
const filePath = `${folder[0]}/${folder[1]}/${folder[2]}`
const fileName = folder[3]
console.log(`文件目录:${filePath}\t文件名称:${fileName}`)
// 在当前目录下,根据文章路径创建多级文件夹
mkdirp(filePath, function (err) {
err ? console.log(err) : console.log(`文件夹${filePath}创建成功!`)
})
// 获取文章内容并保存文件
http
.get(url, function (res) {
let html = ''
res.on('data', function (chunkBuffer) {
// 原网页是gb2312的编码,需要进行解码,避免乱码
html += iconv.decode(Buffer.from(chunkBuffer), 'gb2312')
/* ******************** 下面是开始优化文章内容 ******************** */
// 新的服务器只支持uft-8,所以要替换html文档内的编码格式
html = html.replace(/gb2312/gi, 'utf-8')
// 把整个文档处理为一行,才能随心所欲的替换
html = html.replace(/\n/g, '【br】')
/*
接下来就是各种replace了
- 移除原来的全局头部
- 移除原来的跟贴模块
- 移除原来的相关新闻模块
- 移除原来侧边栏的头条模块
- 移除原来侧边栏的要闻模块
- 换成新的统计代码
- 过滤掉原有写死的文章域名变成相对地址
*/
// 处理好内容,要把换行还原回来
html = html.replace(/【br】/g, '\n')
})
res.on('end', function () {
// 将抓取的内容保存到本地文件中
fs.writeFile(`${filePath}/${fileName}`, html, function (err) {
if (err) {
console.log(`保存${filePath}/${fileName}时出现错误!`)
} else {
console.log(`文件${filePath}/${fileName}保存成功!`)
}
})
})
})
.on('error', function (err) {
console.log('错误信息:' + err)
})
})成果预览
一切顺利,最终爬了有将近 150 篇文章,数据量说大不大,但如果人工处理肯定是不小(至少创建层级文件夹就会累死人)。
刚搞完这次需求,需求方又找过来说还会有个网站想迁移,emmm,坐等新一波挑战了~