在 404 页面投放走失儿童信息,这不是什么新鲜事了,到现在起码有近 10 年的历史,本来腾讯公益也有提供一个公共的 JS 文件可以直接调用,但是发现,数据竟然不更新了…… 2021 年都过去了快一半,JS 提供的数据源竟然还停留在一年前甚至更久,甚至我搜了一下里面的一些孩子信息,在腾讯 404 的 “最新” 数据源里,竟然有一个小宝宝已经成为了天使……
这样的数据源对需要帮助的孩子,以及对已经找回 / 遇难的孩子来说,都是另外的一种 “伤害” ,为了让最新的求助信息能够得到曝光,所以昨晚在搜索最新数据源接口无果的情况下,简单折腾了一个小爬虫从宝贝回家的官网上直接抓取最新的数据。
考虑到 404 页面的触发量不高,所以才采取了爬数据的方式,如果宝贝回家官网的工作人员觉得这个方式不妥当,请发邮件联系我处理掉。
我的邮箱 chengpeiquan@chengpeiquan.com
也希望有认识当前负责 腾讯公益 404 页面 的朋友们,帮忙告知一下数据源停更了的问题。
为什么突然关注这事
很久没采购成箱的东西了,大部分情况下都是零零散散的京东散件或者天猫半日达,一个购物袋就给我装了送过来(低成本换来的高效率,连个箱子都木有……)
周末刚好在天猫超市买了箱东西,开箱一看,发现箱子里面印刷上了走失儿童的信息,感动!突然想起很久没有关注到这方面的信息了。

自从各种 APP 横行和移动端浏览之后,对于各类网页版的新闻网站,都看的比较少了,所以也很久没有看到这个走失儿童的 404 信息。
想想其实自己的博客也可以挂一个,能帮助多少是多少,对于走失的孩子们来说,这也是黑夜里的一点亮光和希望。
需求分析
天猫超市这个是基于支付宝的团圆小程序的数据,但是我找不到官网,而且它也不是展示寻人信息的平台,更多的是作为一个报警平台使用,所以我也没有想去抓包看请求,因为也没有自己需要的数据。
那么还是得看一下 腾讯公益 404 页面 ,来到这里本来我觉得挺好的一个现成数据源,拿来用就是了,但当接入完,发现竟然,???,就如本文开头所说,都很老的数据,虽然上面有些孩子可能依然还在被寻找中,但这样会导致更多需要帮助的孩子失去了曝光机会。
因为数据都是来自于 宝贝回家寻子网,去官网看了一下,发现官网和官方论坛上的信息是非常的新,在衡量了论坛数据源和官网数据源的优劣势之后(论坛格式不统一,图片排序不规则也导致不知道哪一张是被寻人的照片),所以决定抓取官网的数据过来。
如何实现
由于官网的模块只有被寻人的列表,所以需要经历两个环节的数据爬取:
一、先爬取模块里的链接,拿到详情页 URL 的数据源列表
这里我借助了 jsdom 来分析页面结构,提取每个人的详情页链接,另外考虑到曝光率的问题,一个列表 35 个人,全部展示不现实,但如果一直按列表顺序截取前 X 个人,又太少(官网的更新频率也不是非常的高),尽量保持第一页的人都有足够的曝光机会,所以这里通过一个 洗牌算法 打乱了排序,再截取前 3 个被寻人的信息去抓取详情。
/**
* 获取要查找的人物数据
*
* 需要先从列表拿到人物详情页的链接,再去详情页爬取具体的数据回来
*/
const getSearchChildrenData = async () => {
let result = []
try {
const RES = await fetch(
`${__CONFIG__.domain}/list.aspx?tid=${__CONFIG__.tid}&photo=1&page=${__CONFIG__.page}`,
)
const RES_HTML = await RES.text()
const DOM = new JSDOM(RES_HTML)
const { window } = DOM
const { document } = window
// 提取列表的链接
const LINK_LIST = document.querySelectorAll('#ti1 dt a')
// 打乱顺序,提取被随机到的前三个
const SHUFFLE_LIST = shuffle([...LINK_LIST]).slice(0, 3)
// 因为还要继续请求,所以需要接受一个异步函数去继续处理
result = await getResultList(SHUFFLE_LIST)
} catch (e) {
console.log(e)
}
return result
}二、抓取详情页的内容,返回每个被寻人的信息
第一步拿到的是一个 a 标签的 DOM 合集,在这里做了一层循环,由于需要等待详情页的爬取完毕后再统一返回,所以这里没有使用 forEach 等方法,只用了传统的 for 去等待每个请求(所以这也是每次只取 3 个被寻人的原因,虽然是公益,但也不希望对官网造成有过多的不良影响)。
/**
* 获取要查找的人物信息列表
*
* 这里是最终要作为接口数据返回的列表
*/
const getResultList = async (domList) => {
const RESULT_LIST = []
for (let i = 0; i < domList.length; i++) {
// 拿到详情页的链接
const A = domList[i]
const URL = __CONFIG__.domain + A.getAttribute('href')
// 需要再去详情页爬取详细的人员信息
const INFO = await getInfo(URL)
RESULT_LIST.push(INFO)
}
return RESULT_LIST
}爬取详情页的时候也是通过 jsdom 去分析页面结构,拿到节点上的文本信息作为 JSON 的值来返回。
/**
* 获取人物的详细信息
*
* 缺失的信息统一处理为不详再返回
*/
const getInfo = async (url) => {
// 要返回的基本信息格式
const INFO = {
photo: '',
name: '不详',
gender: '不详',
birthday: '不详',
missingDate: '不详',
missingPlace: '不详',
feature: '不详',
url: url || __CONFIG__.domain,
}
// 更新详情页里的字段数据
try {
const RES = await fetch(url)
const RES_HTML = await RES.text()
const DOM = new JSDOM(RES_HTML)
const { window } = DOM
const { document } = window
// 提取照片
const PHOTO_DOM = document.querySelector('#_table_1_photo img')
const PHOTO = __CONFIG__.domain + PHOTO_DOM.getAttribute('src')
INFO['photo'] = PHOTO
// 提取个人信息
const INFO_DOM_LIST = document.querySelectorAll('#table_1_normaldivr li')
INFO_DOM_LIST.forEach((item, index) => {
// 提取过滤掉标签后的文本
const TEXT = item.innerHTML.replace(/<span>.*<\/span>/, '') || '不详'
// 根据索引判断要存储的字段
switch (index) {
case 2:
INFO['name'] = TEXT
break
case 3:
INFO['gender'] = TEXT
break
case 4:
INFO['birthday'] = TEXT
break
case 6:
INFO['missingDate'] = TEXT
break
case 8:
INFO['missingPlace'] = TEXT
break
case 10:
INFO['feature'] = TEXT
break
}
})
} catch (e) {
console.log(e)
}
return INFO
}最终是得到了一个 JSON Array 返回给接口,因为我的服务端程序是用的 Express ,所以在 Express 的路由文件里,读取刚才写好的方法,拿到数据后作为接口的数据返回即可。
const getSearchChildrenData = require('../api/getSearchChildrenData')
// 接口:宝贝回家
router.get('/api/searchChildren', async (req, res) => {
const data = await getSearchChildrenData()
res.send(data)
})相关的代码都托管在仓库里了,需要的同学可以参考,部署到自己的服务端生成 API 就可以调用。
传送门:search-children-api-example
最终效果
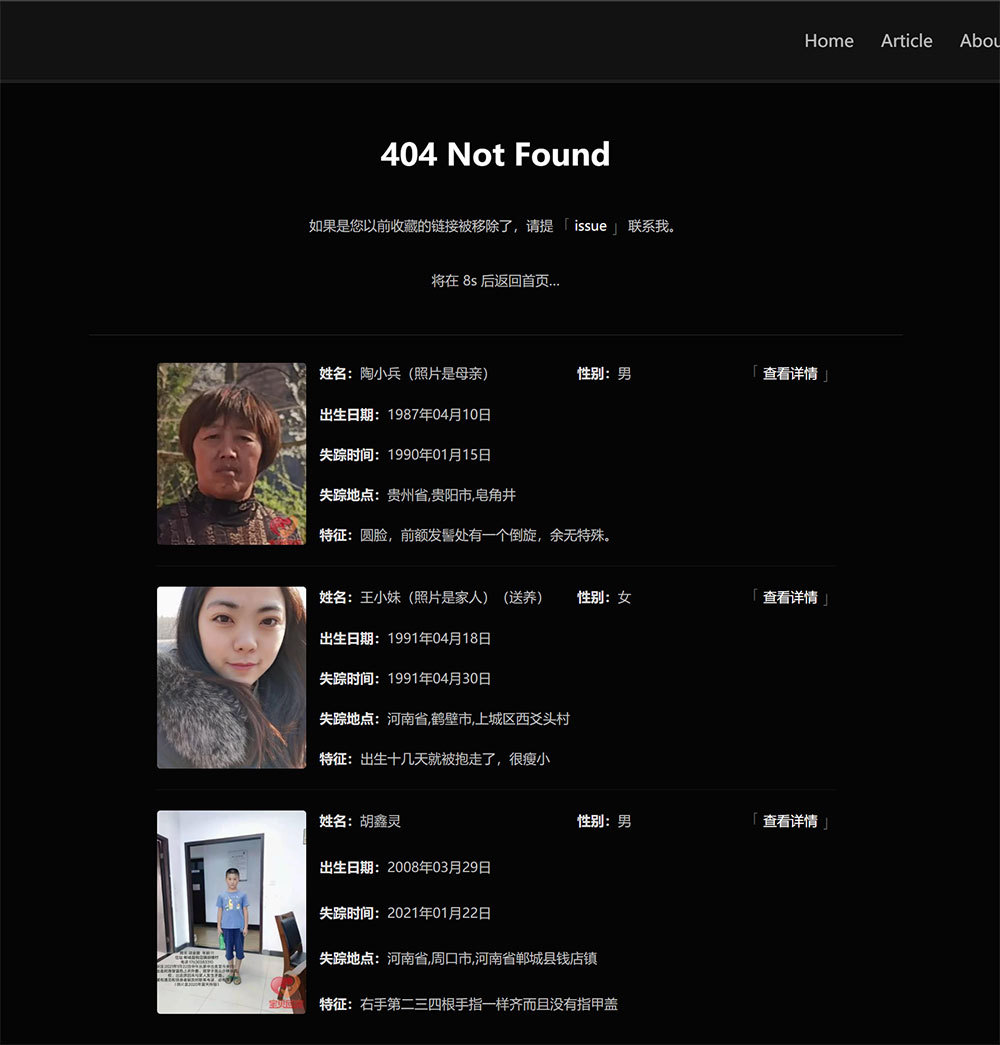
最终 404 页面上,走失儿童的效果预览如下图,考虑到博客里目前用户的访问占比,以及宝贝回家官网本身的适配程度(官网没有手机版和英文版),所以目前只投放在博客中文版的桌面端。
可以戳: 404 或者随便打一个不存在的路径查看效果(因为需要走多次请求才能拿回数据,所以倒计时我改成 10s 了)。
当然以上是作为一个技术男力所能及的一点小公益贡献,生活里时不时还是有机会可以帮助到更多的人,比如之前在知乎就看到一个新闻: 以偶像之名——百站联合公益计划 以爱心共筑校园 ,追星的同时做公益,也是一个特别好的方式,希望有能力有影响力的人,能够多带头多响应,让世界更好!
以上。